Weekly Analysis - Bootstrap Resampling
In this part of the intermediate series, we make sit/start decisions using bootstrap resampling with sklearn.
In this part of the intermediate series, we make sit/start decisions using bootstrap resampling with sklearn.
If you have any questions about the code here, feel free to reach out to me on Twitter or on Reddit.
If you like Fantasy Football and have an interest in learning how to code, check out our Ultimate Guide on Learning Python with Fantasy Football Online Course. Here is a link to purchase for 15% off. The course includes 15 chapters of material, 14 hours of video, hundreds of data sets, lifetime updates, and a Slack channel invite to join the Fantasy Football with Python community.
In this post, we'll cover how to use a statistical technique known as boostrap resampling to be able to generate confidence intervals (boom/bust) scores for different players for your in-season analysis. This can be especially useful when making sit/start decisions.
Boostrap resampling is a method of taking a small sample from a larger population and repeatedly sampling with replacement to estimate the population.
In this post, I chose to take the projected points for Juju Smith-Schuster, Devante Parker, and Tyler Boyd and boostrap resample the results to find ceiling/floor values for all 3 players and make a sit/start decision. These are 3 players I'm considering plugging in to my WR2 spot for this year's week 1, but you can use any players you want. You'll have to find the projected points for each platform I chose below manually. It did take me 20-30 minutes to actually find all the projections and input them in to Pandas, but this is something I hope to automate with a web scraper and expose through an API, eventually.
Boostraping is when we take a sample of a larger population (in this case, projected fantasy points) and repeatedly resample with replacement until we can make an estimate of the larger population. "With replacement" here means that when an element of the original array is randomly selected, it is not taken out of the original array and can be randomly chosen again.
Essentially, we are going to be taking each player's projected points and take a single sample from the array we pass in. When we select an element, we append it to a new array, our boostrap array. We do this n times where n is the size of the original array. In other words, our bootstrap array is going to be the same length as our original array. Because we are sampling with replacement, our boostrap array might have values from the original array appear once or more times, and also not contain elements from the original array at all.
We then take the mean of that new bootstrap array, and append that value to a list where we store all of the means from our bootstrap arrays up to n_iterations where n_iterations by default is going to be 10000. This list of means will be of size n_iterations.
In other words, we repeat that boostraping, taking the mean process 10000 times, unless specified otherwise through a keyword argument to a function we'll write up below.
From there, we have an estimate for the mean that theoretically generalizes to the larger population. We can then estimate a 95% confidence interval by using the np.percentile function.
| Player | Sleeper | FanDuel | ESPN | FantasyPros | fftoday | ffcalculator | walterfootball | |
|---|---|---|---|---|---|---|---|---|
| 0 | Juju Smith-Schuster | 16.20 | 15.84 | 14.6 | 15.6 | 14.6 | 16.2 | 18.0 |
| 1 | Devante Parker | 13.92 | 12.20 | 12.5 | 11.7 | 13.1 | 14.0 | 10.0 |
| 2 | Tyler Boyd | 14.23 | 11.92 | 11.7 | 12.3 | 7.6 | 14.5 | 10.0 |
| Juju Smith-Schuster | Devante Parker | Tyler Boyd | |
|---|---|---|---|
| 0 | 15.685714 | 11.814286 | 12.420000 |
| 1 | 16.205714 | 12.500000 | 12.014286 |
| 2 | 15.771429 | 13.120000 | 11.842857 |
| 3 | 16.314286 | 12.634286 | 11.600000 |
| 4 | 15.811429 | 12.688571 | 12.700000 |
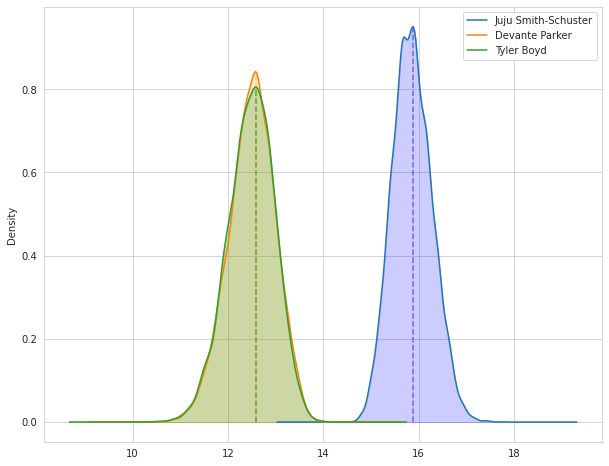
As we can see from the visualization and the text output, Juju is the clear winner. He has a projected mean output of 15.86 and a ceiling of 16.58. His floor is well above the means and ceilings of Boyd and Parker as well.
Thanks for reading, good luck with your season!

